NOTICE: This page is frequently updated as new features and training materials are created. Questions may be sent to info (at) insitulabs.org
THE ISL DATA SYSTEM OVERVIEW
PURPOSE
Historically, biological sample collection at remote field locations and laboratory analyses have been carried out independently of one another, by separate institutions and/or groups of stakeholders. Most data systems that support these distinct parts of the research process have been developed in isolation, and remain 1) unintegrated or 2) unadaptable to diverse environments with power and data service constraints. As we endeavor to set-up more fully-functional molecular laboratories in the field (in-situ), our goal is to seamlessly integrate biological sample collection with laboratory sample analysis and data sharing applications in an intuitive, user-friendly, and secure way.
ACCESS
We strive to build off of other prior openware initiatives, and remain committed to making all our data system tools low cost, and where possible, completely free for scientific research, public health, and conservation applications. The system is fully supported for all official members of the ISL initiative, external parties should send email inquires to info (at) insitulabs.org.
DESCRIPTION
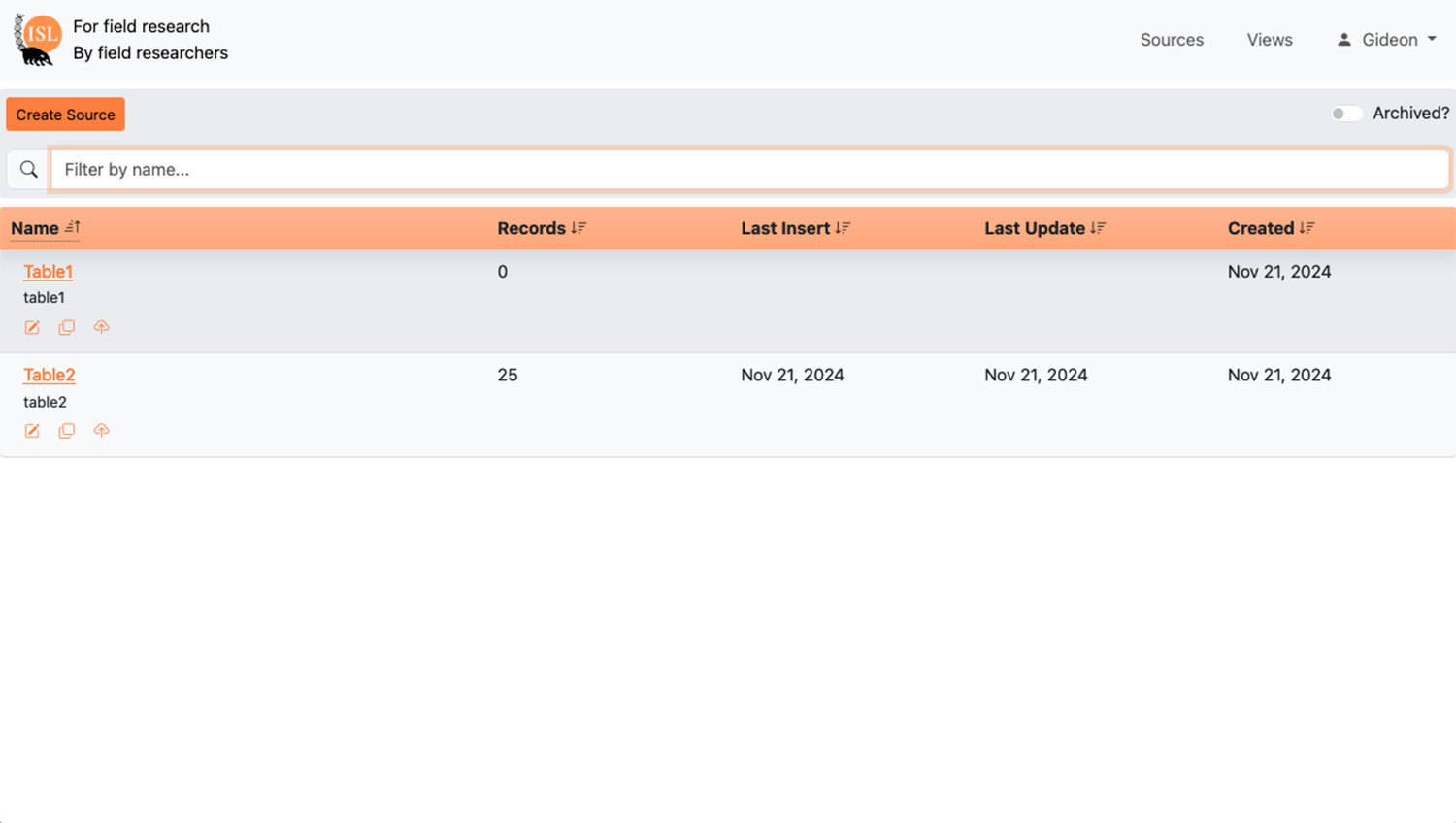
The In Situ Laboratory Data System is a combination of tools to capture, organize, clean, and synchornize data for a variety of downstream applications. The following describes the flow of data:
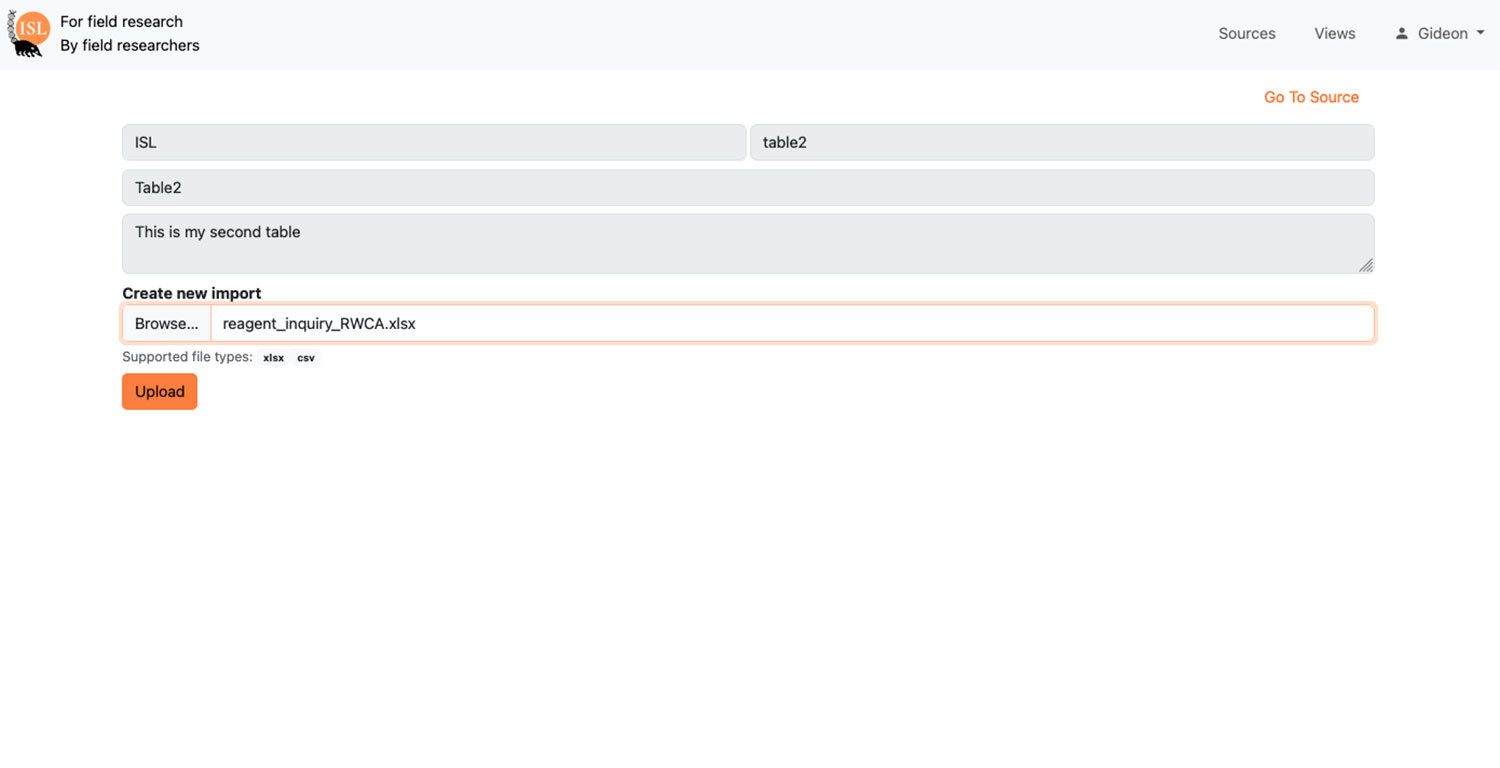
- Data enters the system via direct entry, spreadsheet upload, or 3rd-party data form collection tools. We recommend the use of digital forms, such as those provided by the Open Data Kit (there are many good options), as they ensure users collect and submit information in standardized ways.
- Data is organized into a MongoDB database platform. MongoDB is similar to other database platforms, but we like how it accepts data in many formats and structures (incl. mixed data types) without complaint.
- Attachments and media are automatically moved into an Amazon S3 server, text and numerical data are stored directly in the cloud database, which is backed-up.
- Users control access and interact with the database via the ISL app, a software designed by field and laboratory research personnel, then implemented and maintained by the ISL technology team.
STRATEGIC OVERVIEW
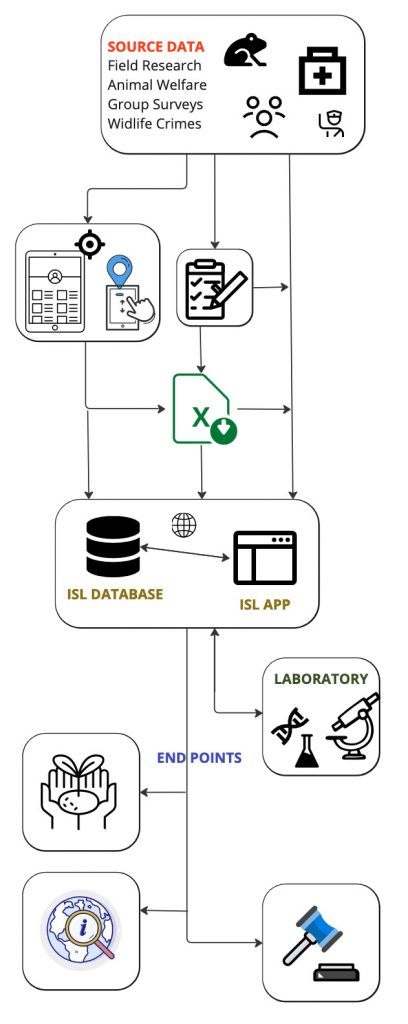
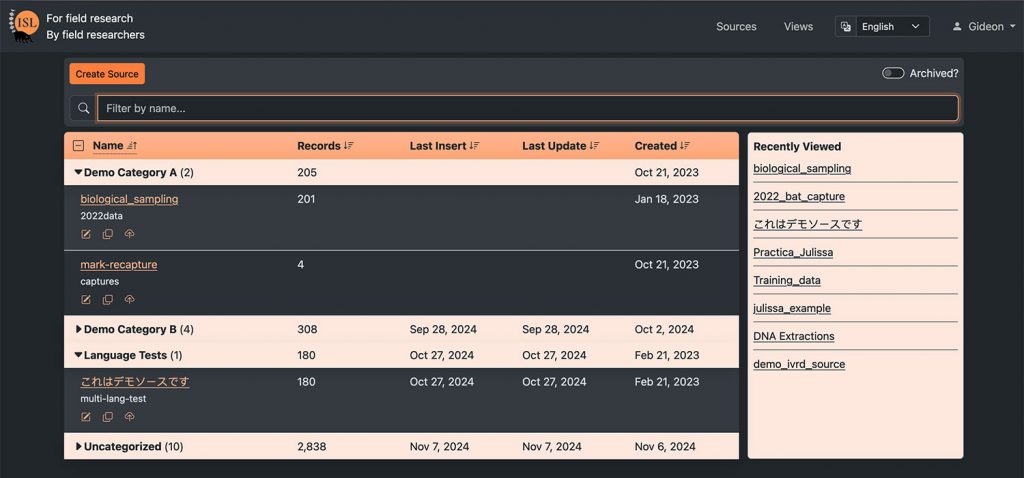
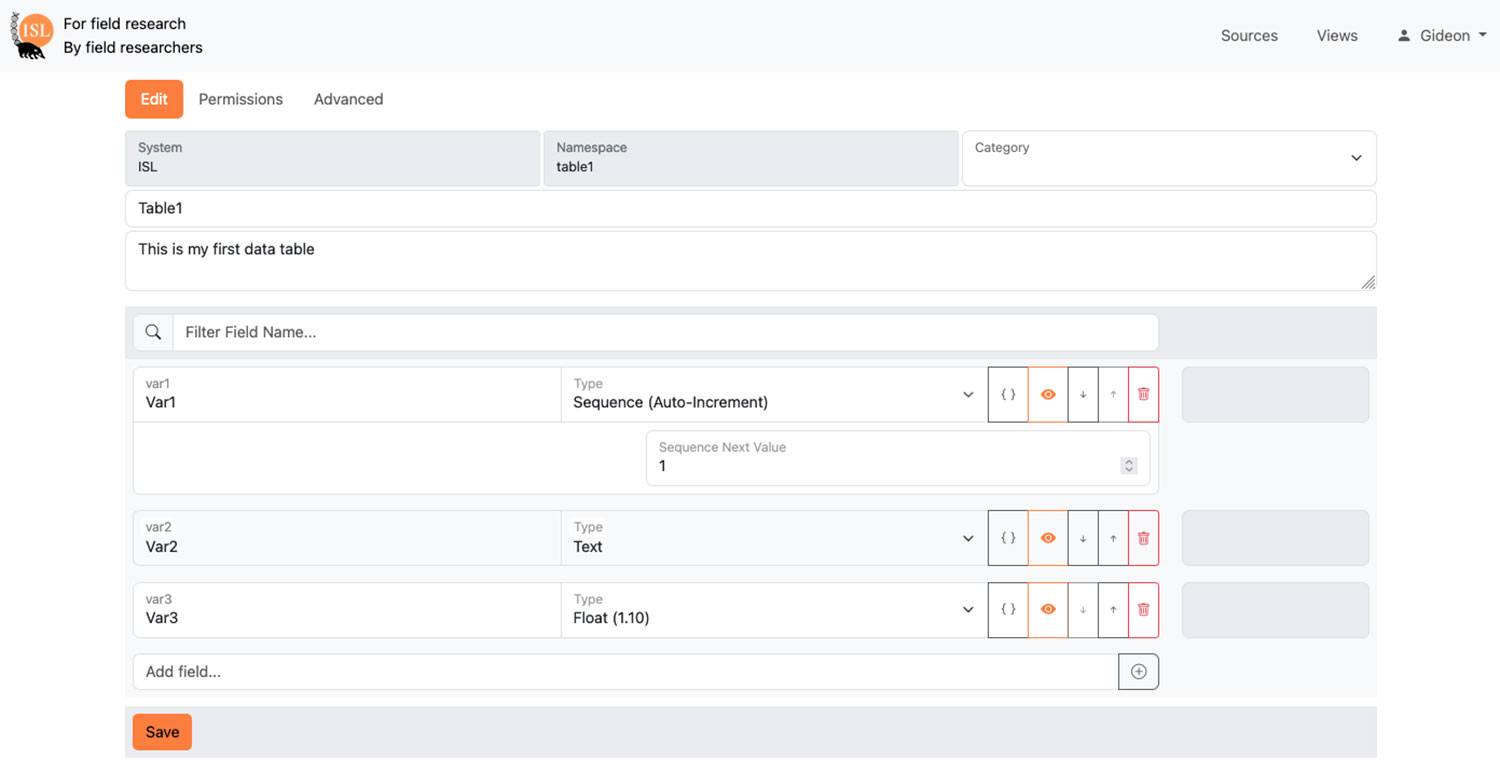
The ISL Data App allows researchers detailed control of a database without requiring programing experience. Basic computer literacy is required.
Key Functionalities – The WHAT and the WHY
| WHAT | WHY |
| Operates on common internet browsers | The system is not tied to Windows, Apple OS, or Linux. |
| Language customization | Each deployment of the system allows any number of language translations. Facilitating international collaborations. |
| Simple graphics and organization | Not built to be flashy, rather it must work when internet bandwidth is limited. Should feel familiar, like browsing a personal computer file system. |
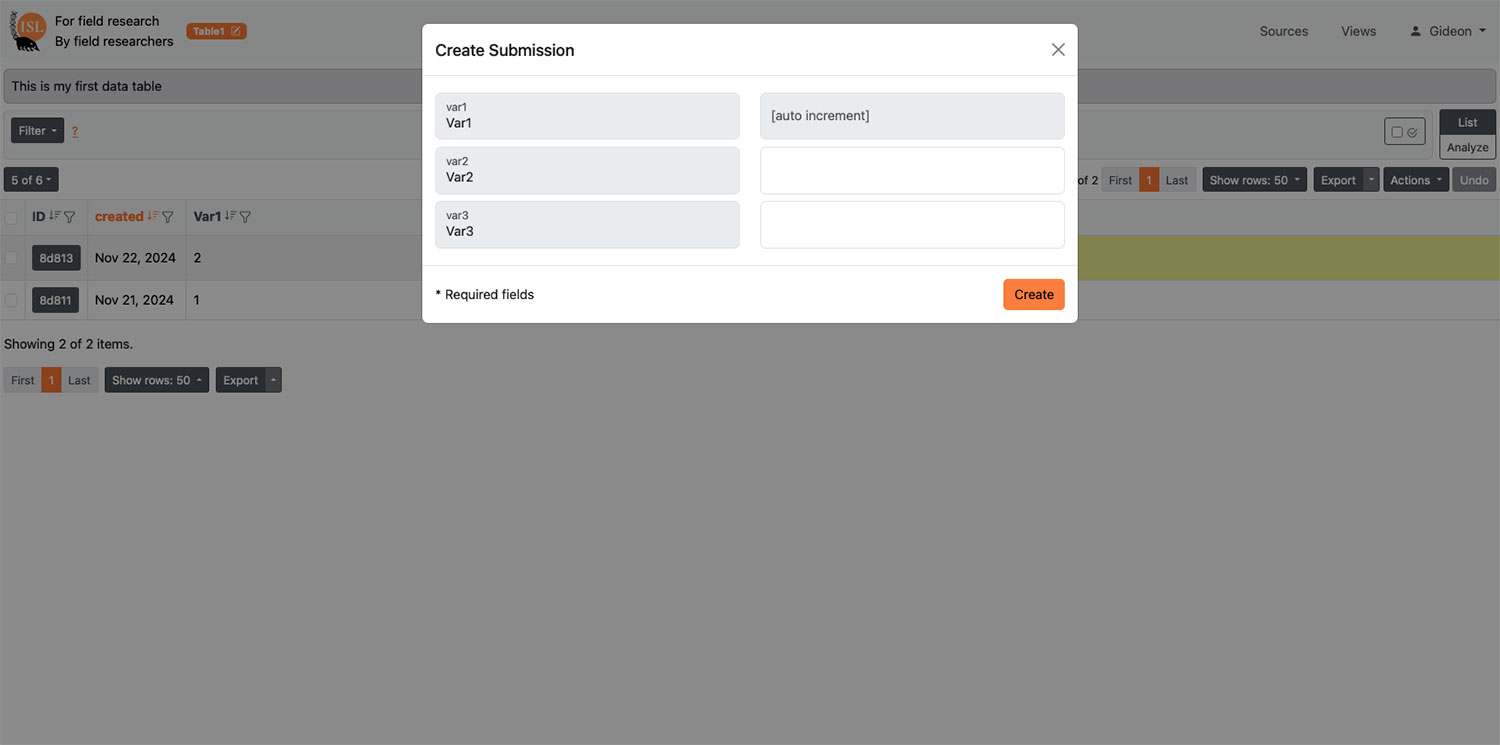
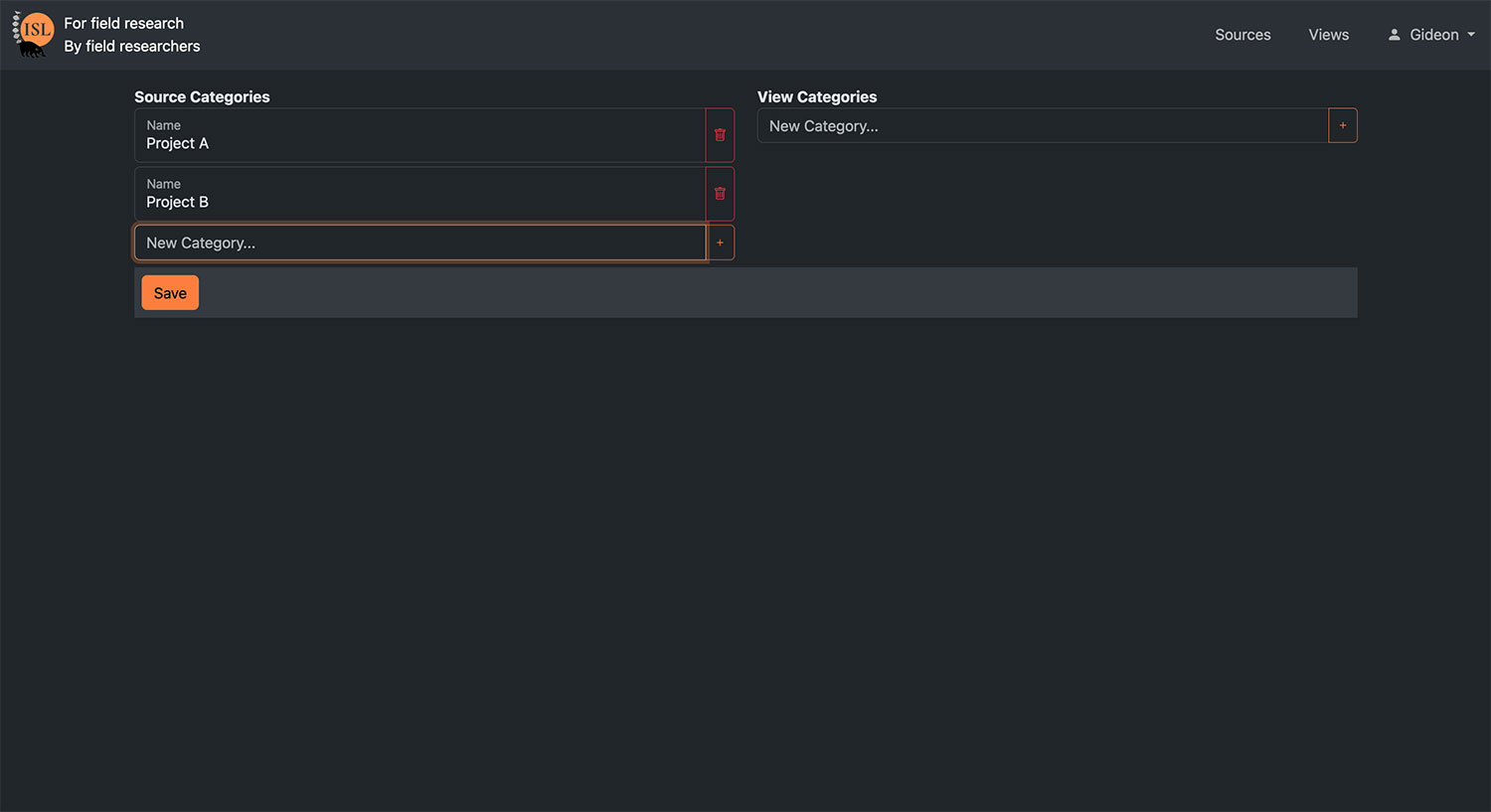
| Customizable to different use-cases | Structure of data tables, custom views, and relationships are controlled by end-user |
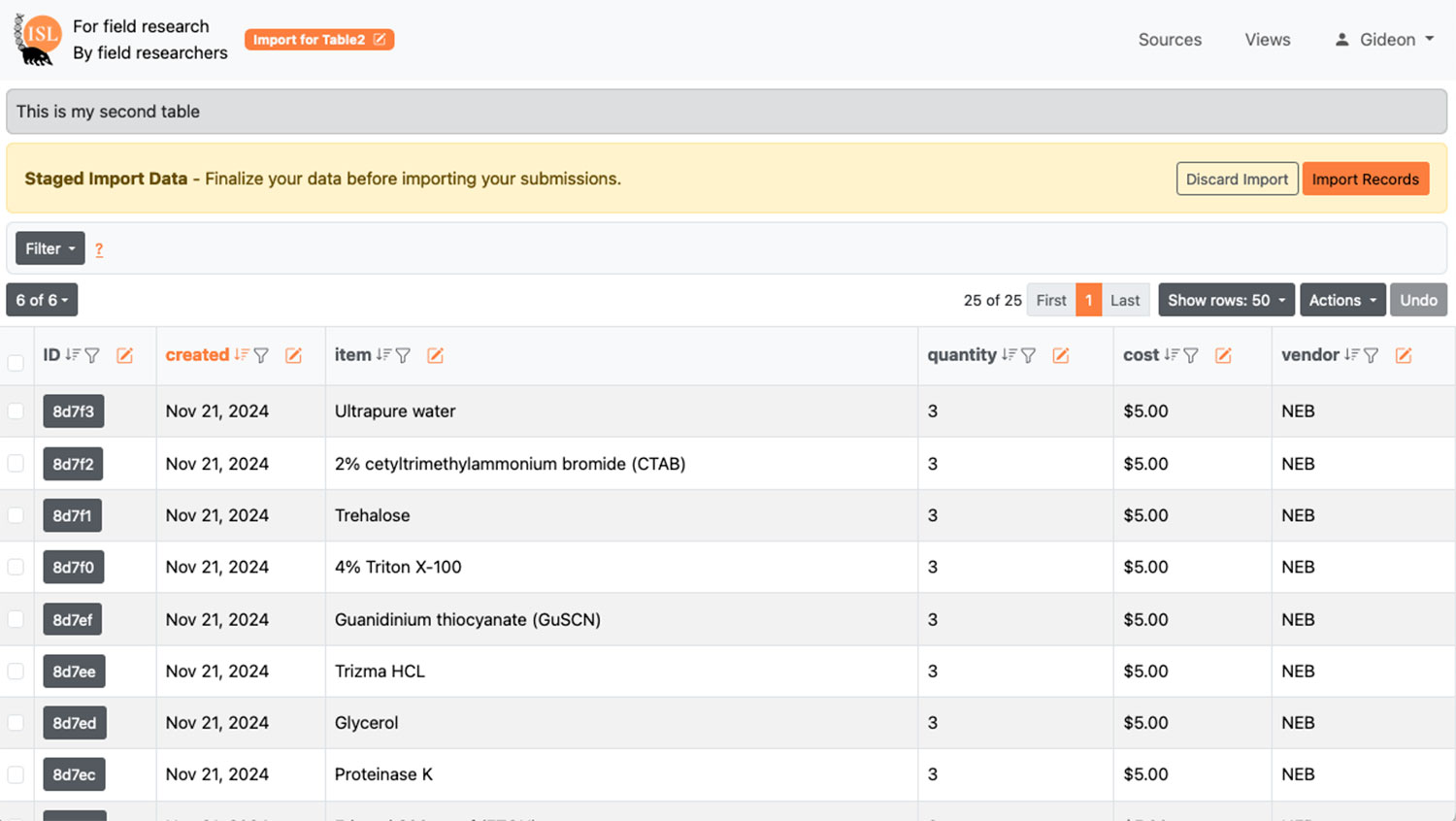
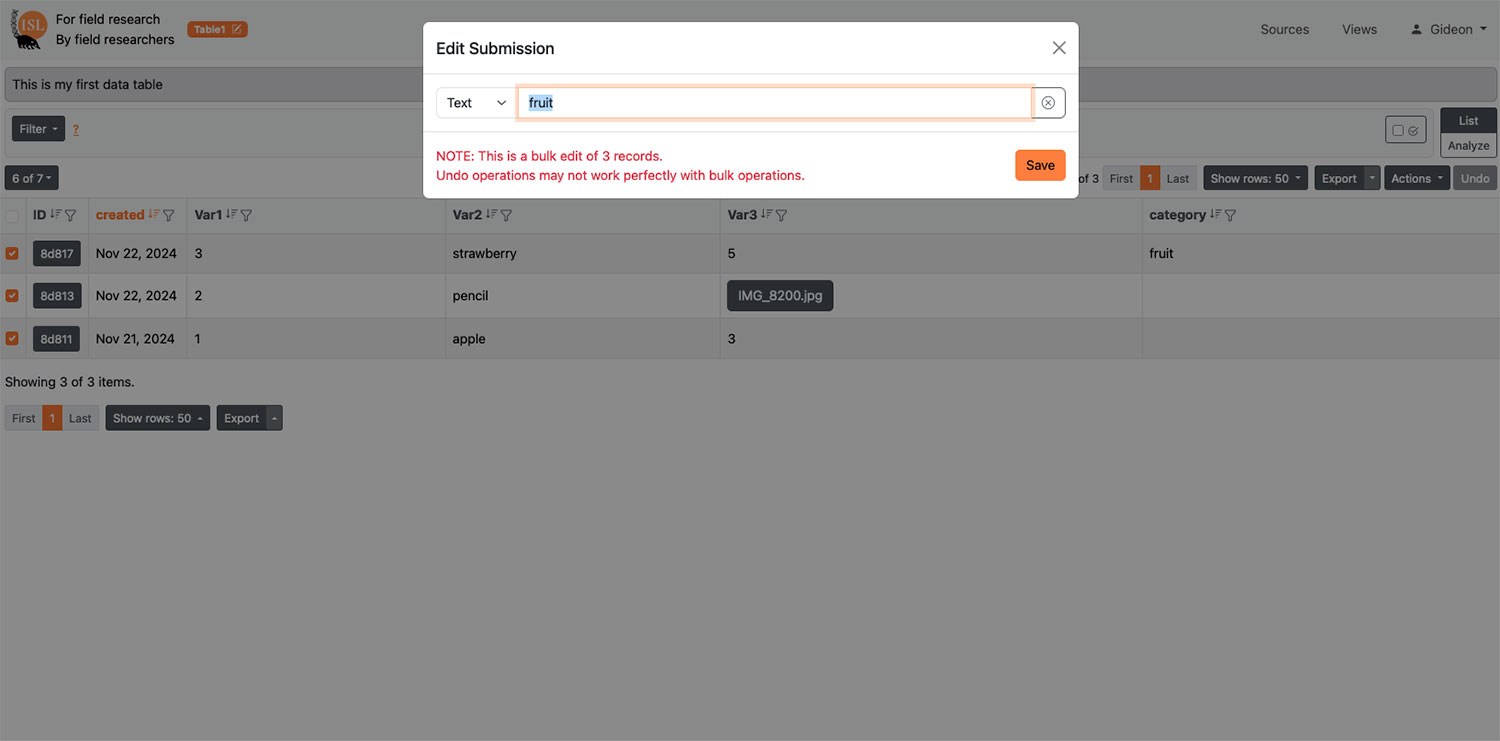
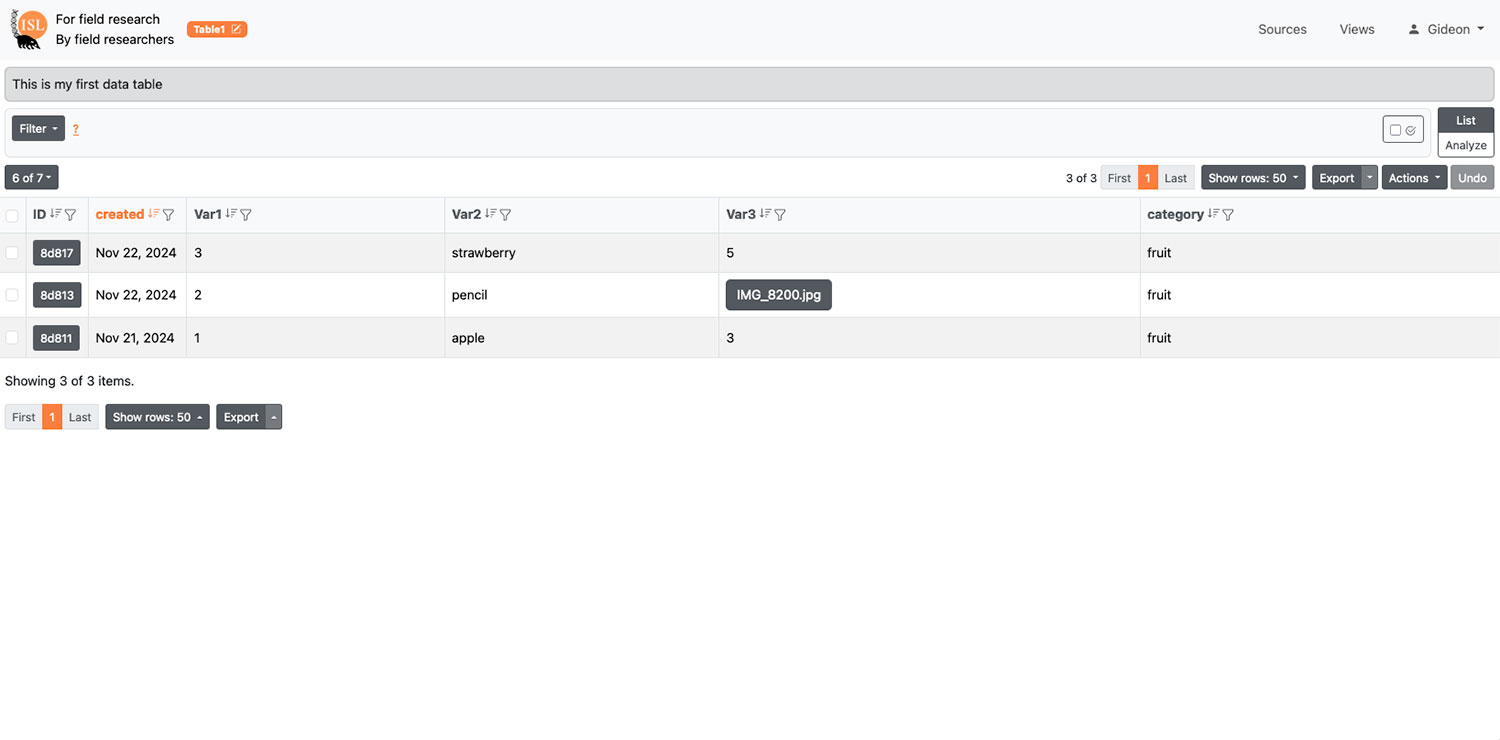
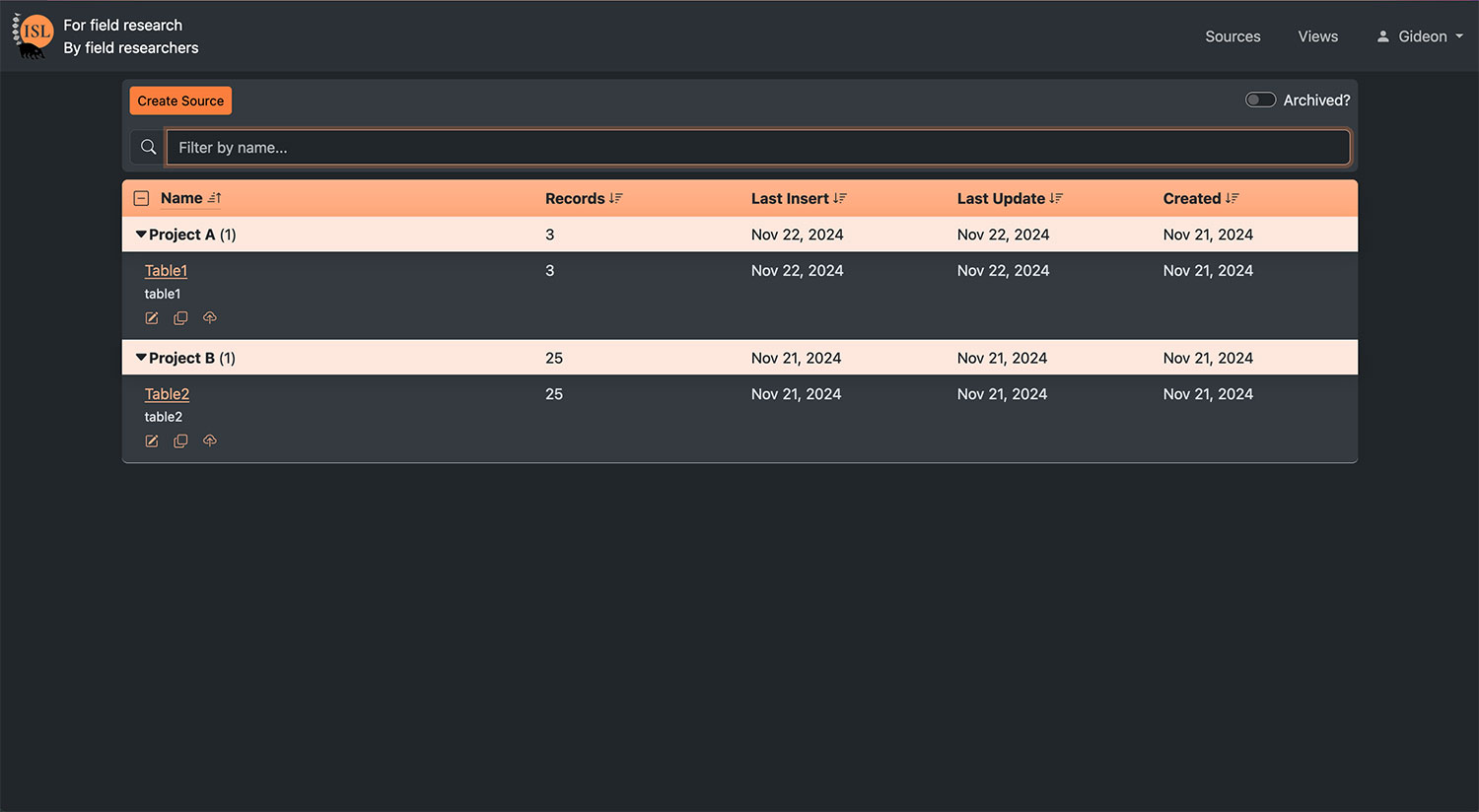
| Simple and bulk data table edit options | Many researchers default to spreadsheets because they cannot change records efficiently |
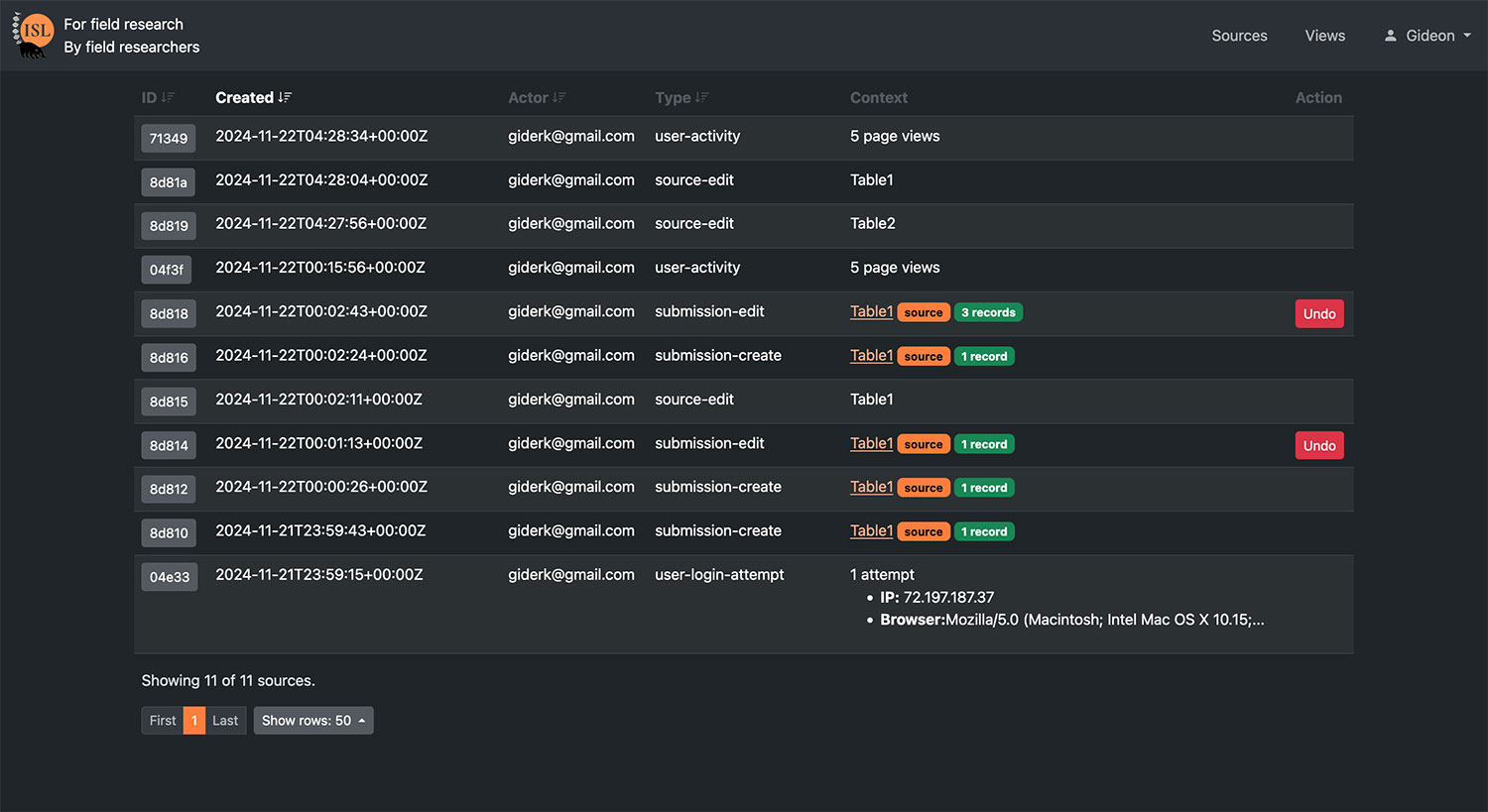
| In-built auditing and operation reversal | All data operations are tracked and easily reversed by permitted users |
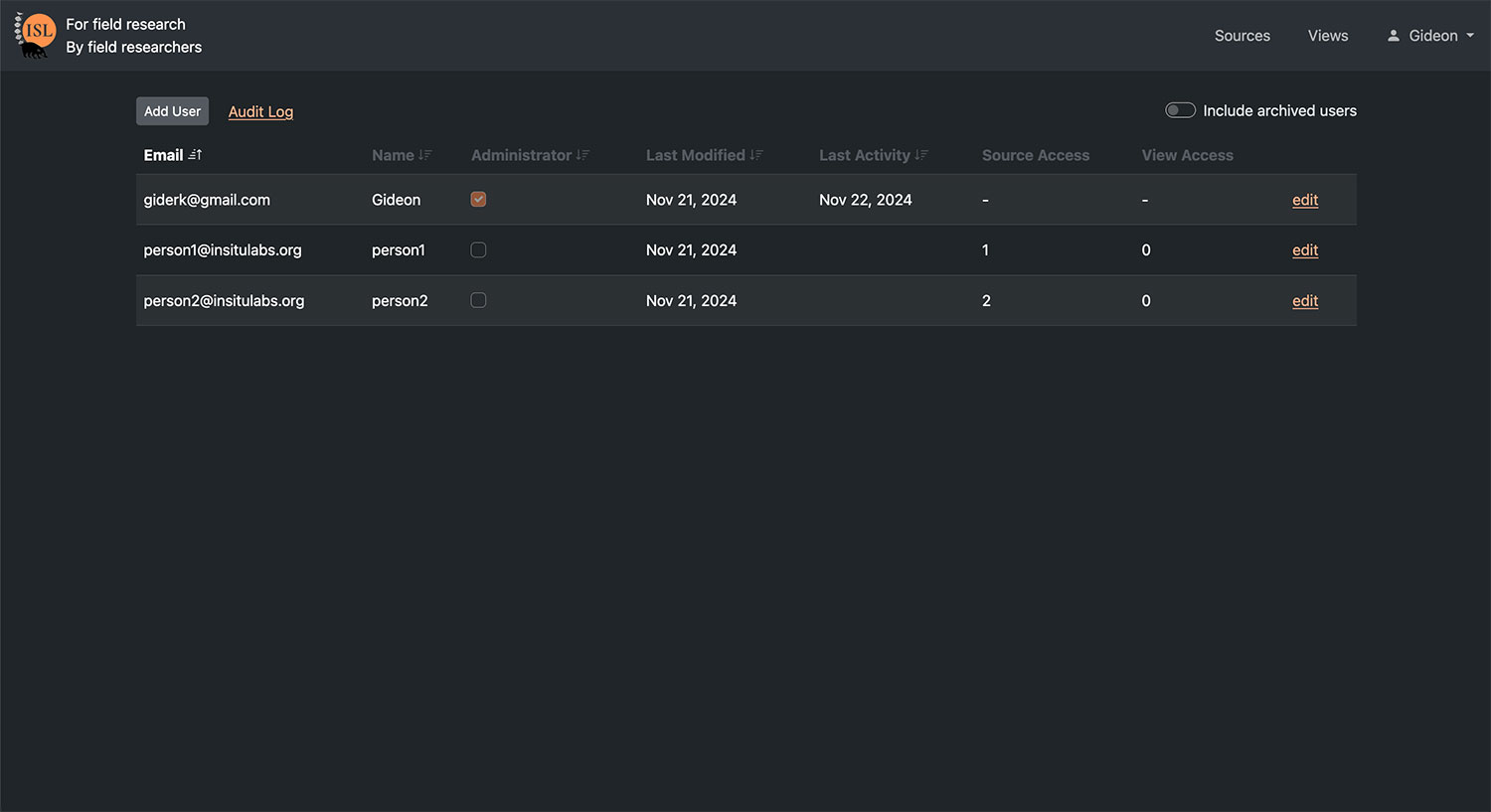
| Specific user access for data viewing and editing | Open collaboration requires giving specific table-by-table and view-by-view access |
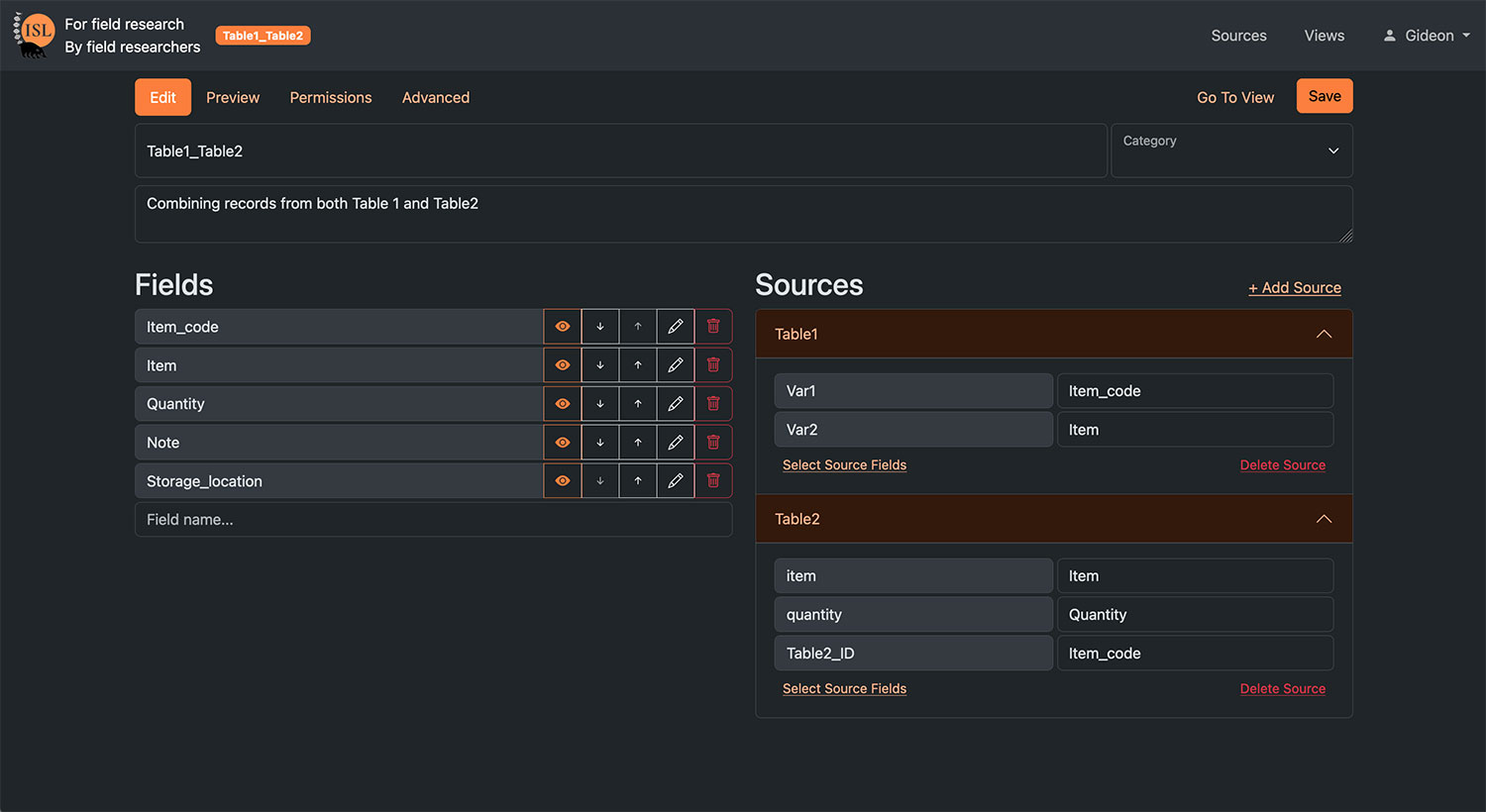
| Cross-table relationships | Easily add one or more links between tables |
| Batch import and update | When it is easier to review data and make corrections outside of the system (i.e. in Excel), efficiently batch update any modified fields. |
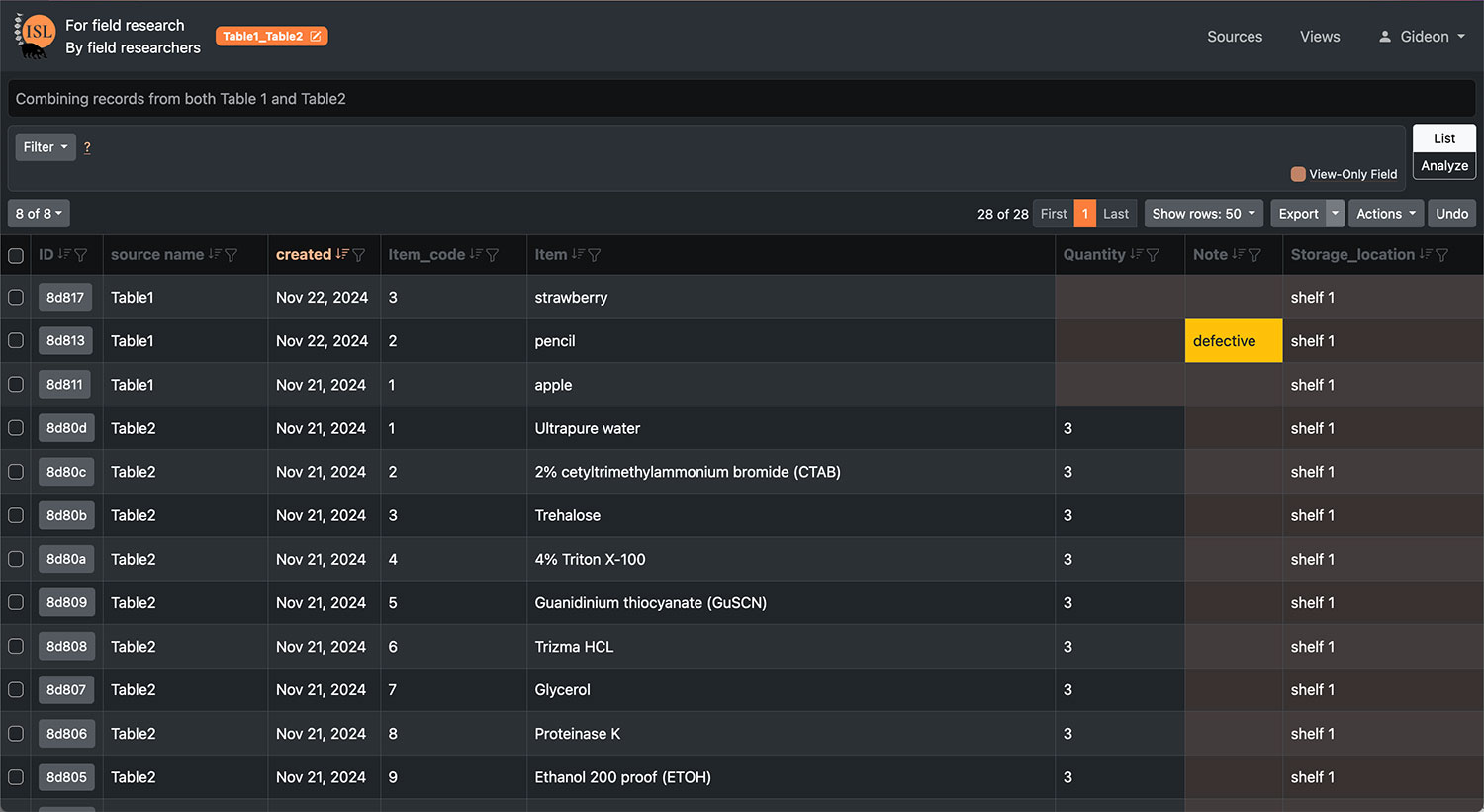
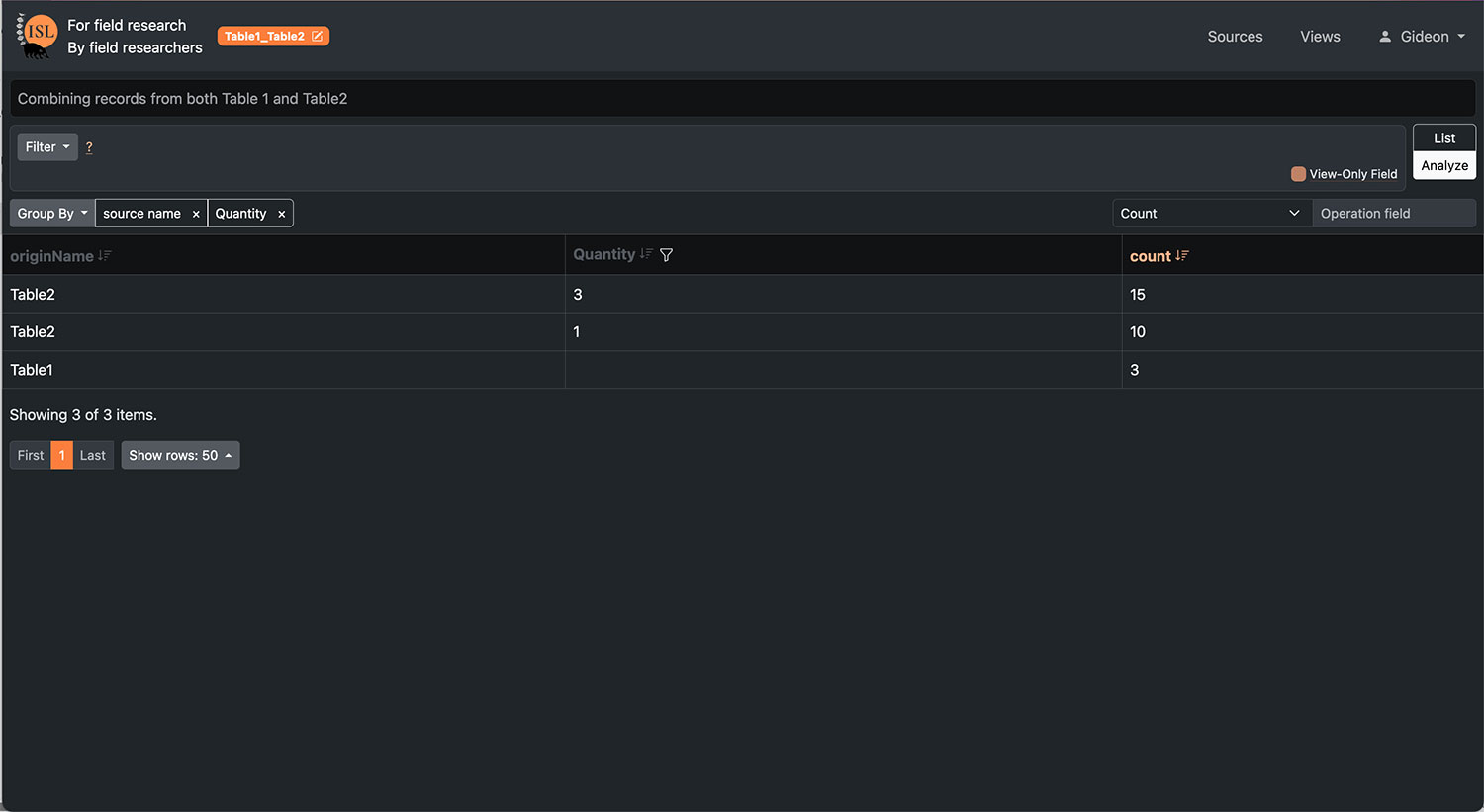
| Data filtering, sorting, summary | Self-explanatory |
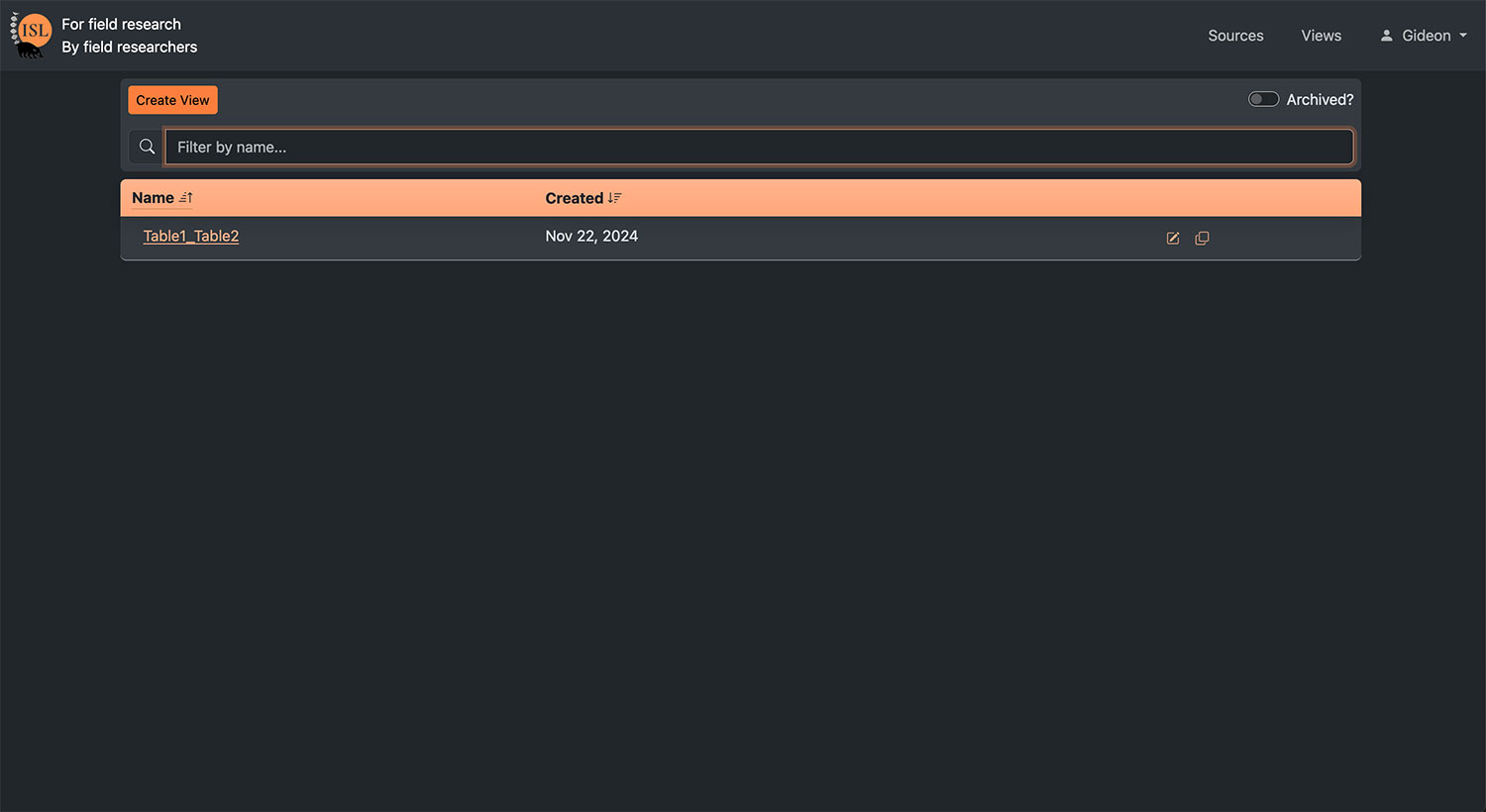
| Custom VIEW creation | Transformations between wide/long data tables, and merge multiple tables together by linked or common variables |
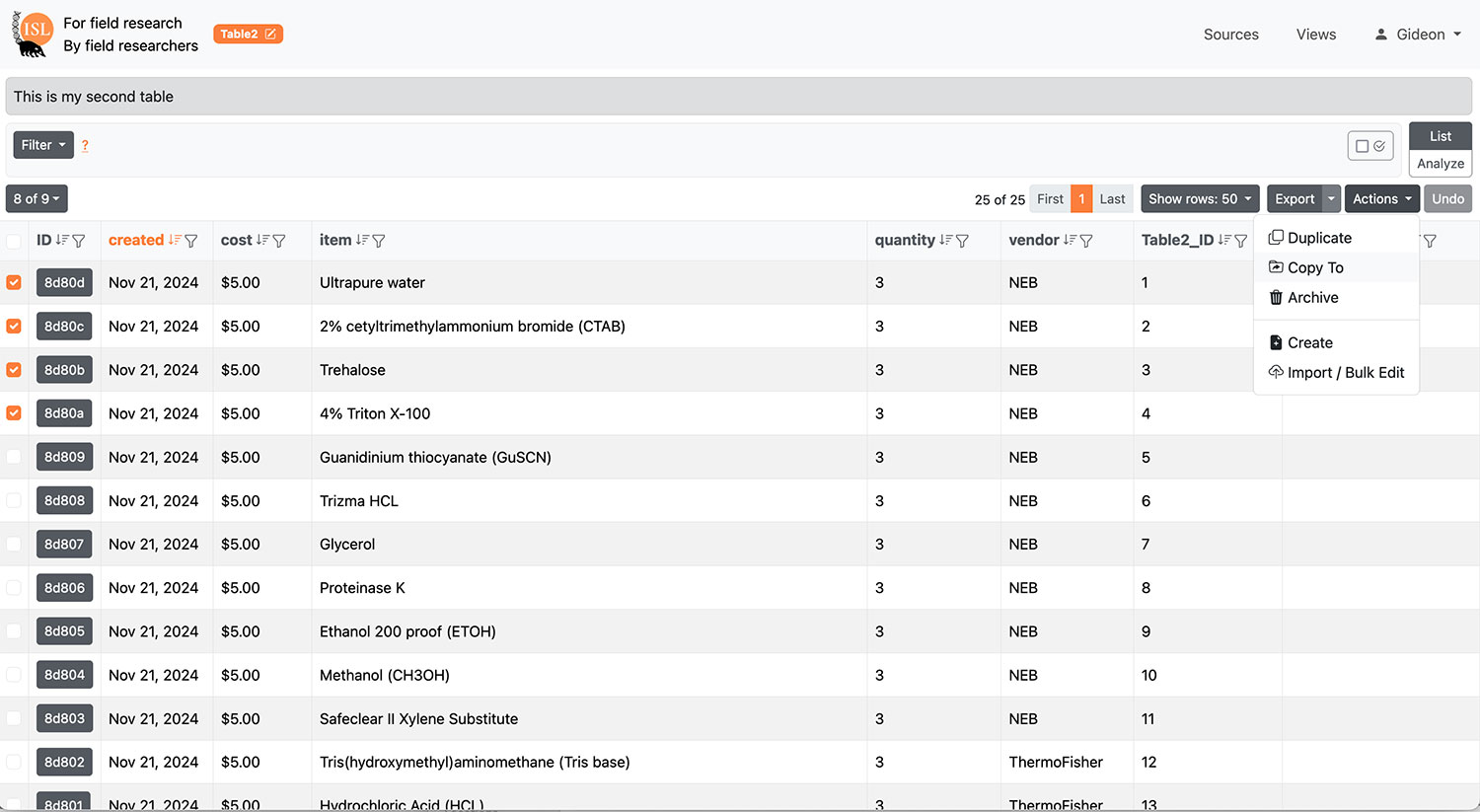
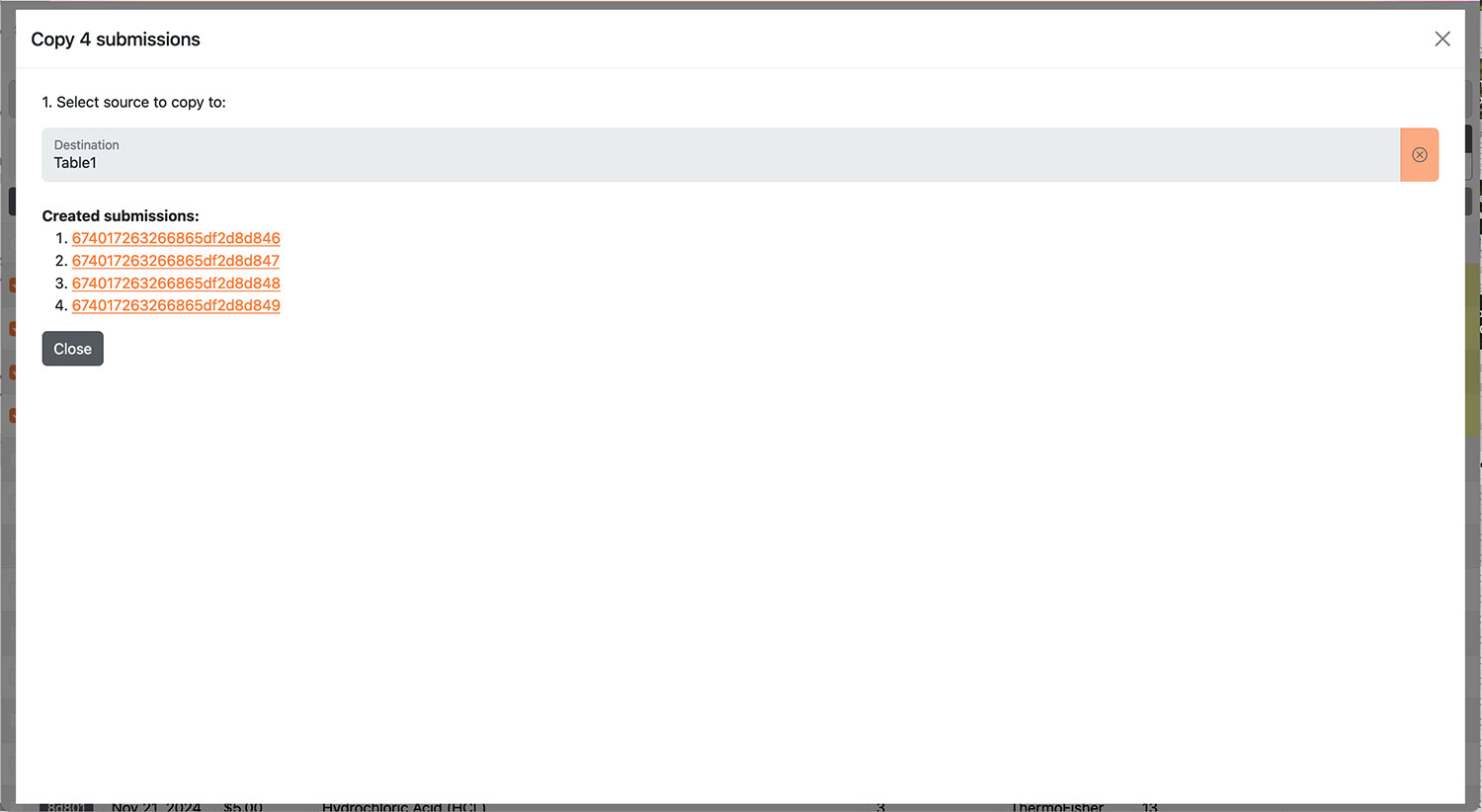
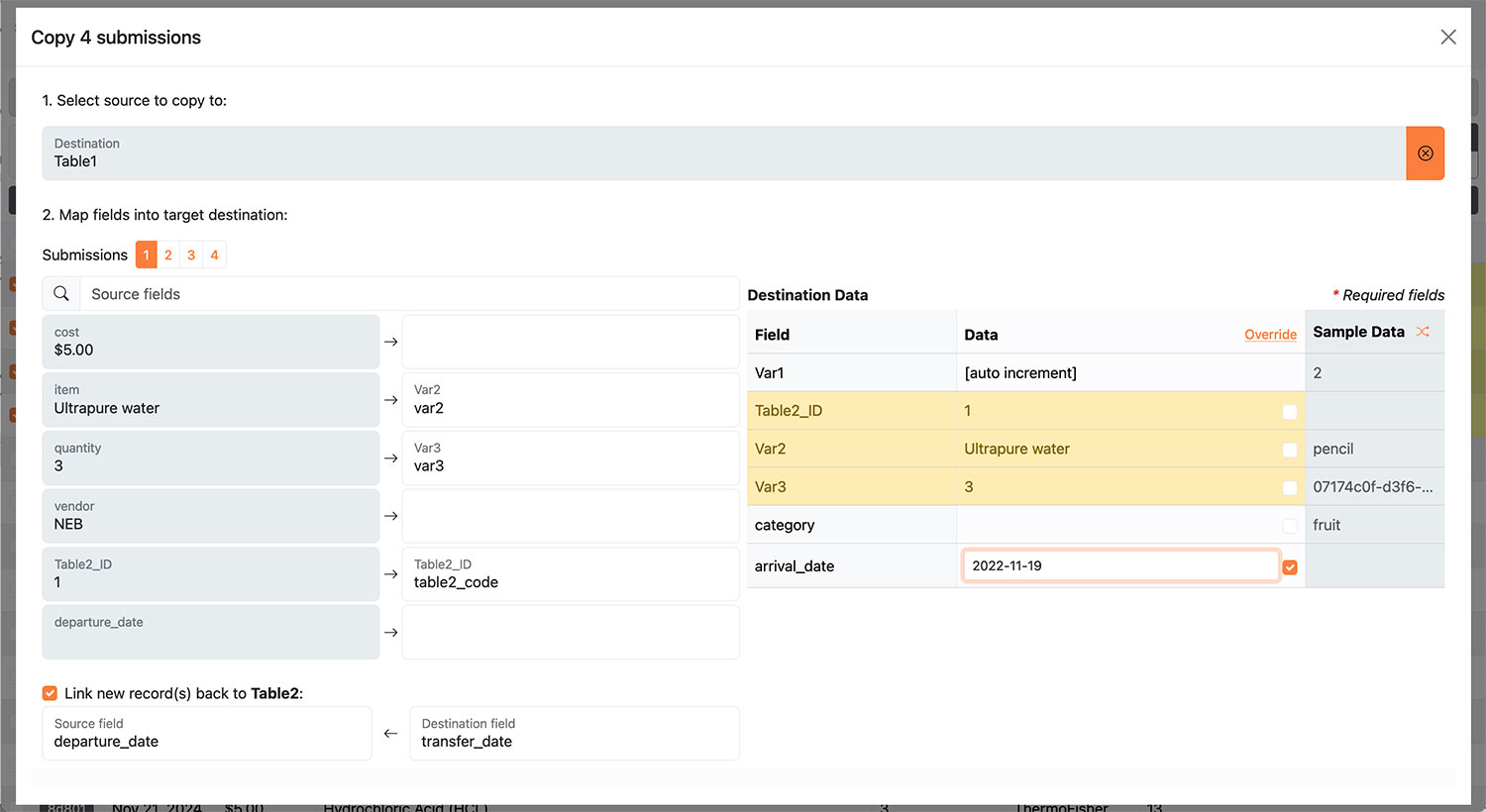
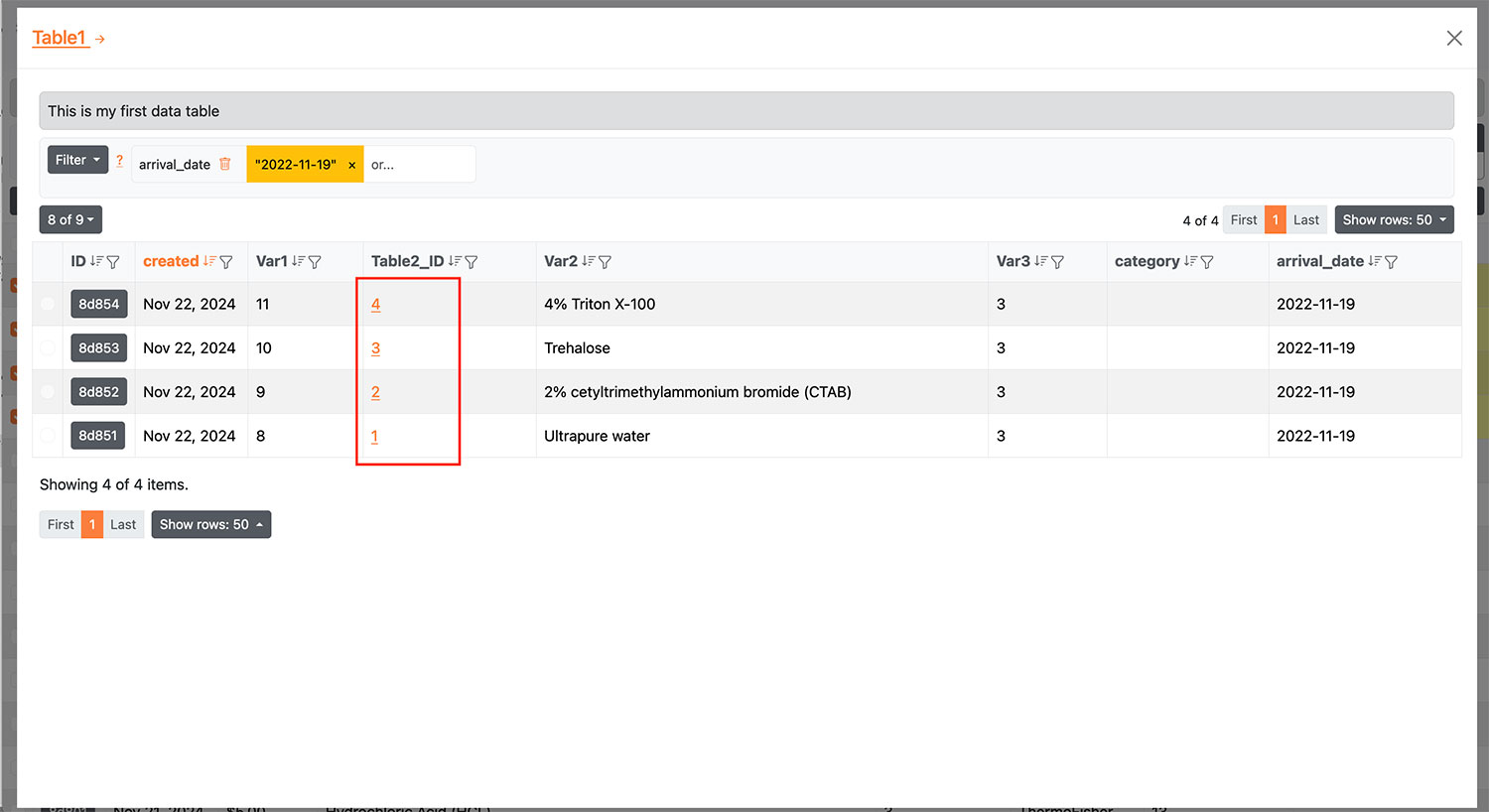
| Data movement and tracking | Move whole or partial records between tables, as in a laboratory or analysis workflow, establishing live links between sources and destinations |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}