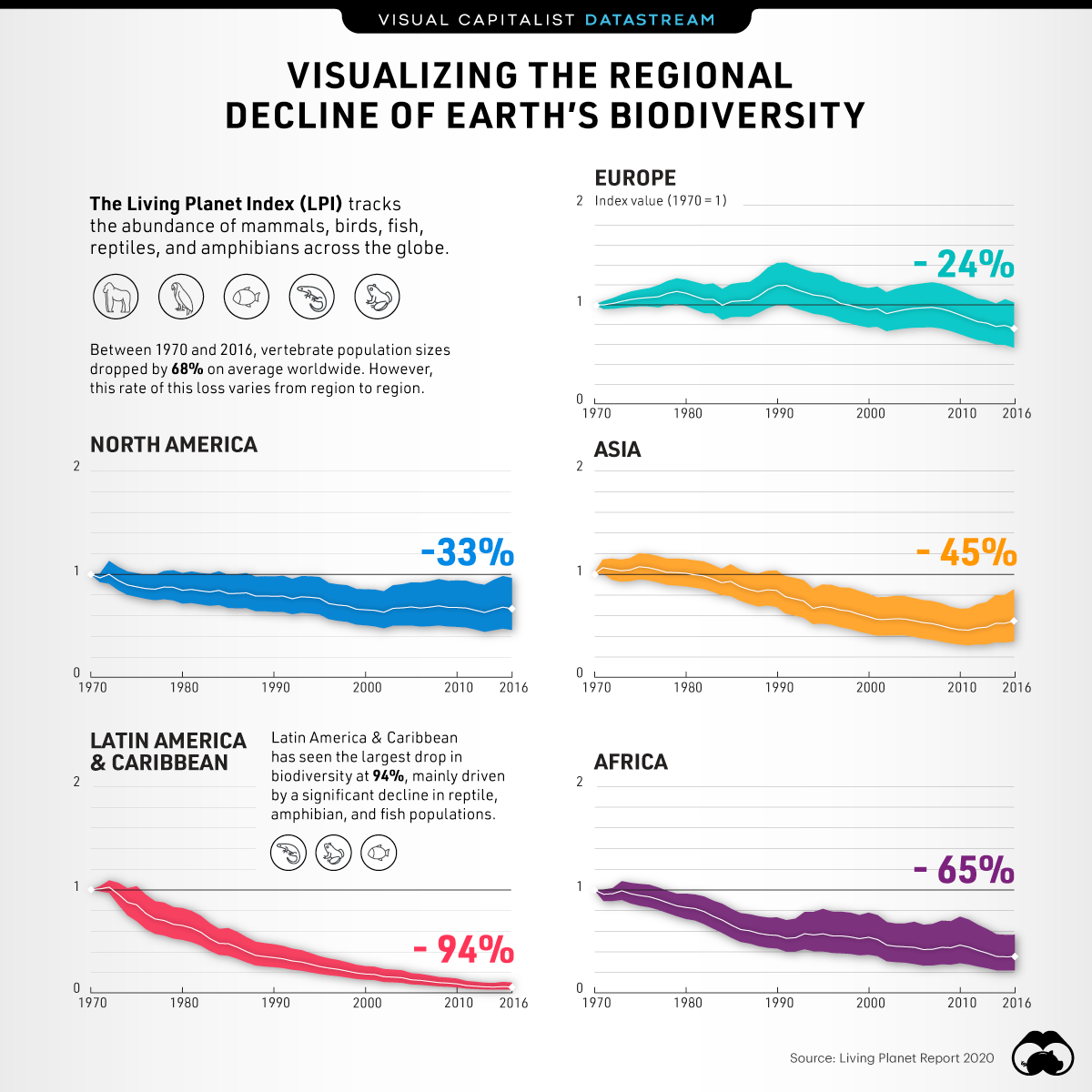
The world’s biodiversity is under threat – that much is undeniable. The primary threats to this biodiversity are related to humans: how we use land, extract resources, and dispose of waste have created myriad downstream threats to global biodiversity. As a result of this, the last 50 years have seen massive declines in populations, based on the Living Planet Index Report as visualized below. Stopping or slowing the rates of decline are of primary importance, but so is documenting the effect of such interventions to be able to choose actions with the most impact on biodiversity conservation. However, to do so, one must employ a toolset focused on describing biodiversity in a standardised, comparable, and reliably accurate manner.

The Barcode of Life Database, or BOLD, was launched in 2007 as an “an informatics workbench aiding the acquisition, storage, analysis and publication of DNA barcode records.” Animals (marker name COI), plants (RBCL and MATK), and fungi (ITS) sequences are curated across multiple taxonomic groups alongside precise morphological and geographic data. There is no better place to deposit sequences at this time, and our work will be hosted as an open access resource (link to be announced shortly).